Backend/Spring
Spring JPA의 @Table 어노테이션에 대해서 알아보자 - name을 어떻게 매핑하는가?
Seyun(Marco)
2023. 11. 29. 23:26
728x90
Spring JPA의 @Table 어노테이션에 대해서 알아보자 - name을 어떻게 매핑하는가?
서론
- Entity와 Table을 매핑하기 위해 사용하는 어노테이션은 @Table 어노테이션 입니다.
- 실제 @Table 어노테이션이 어떤 역할을 해주는것인지, 또한 각 속성값을 어떻게 동작시키게 되는지에 대해서 알아볼 예정입니다.
- 코드를 살펴보다가, 대체 @Table 의 name은 어떻게 매핑이 되는건지?에 대한 궁금증이 생겨서 그걸 중점적으로 이야기를 나눠보도록 하겠습니다.
어노테이션 코드 살펴보기
package jakarta.persistence;
import java.lang.annotation.Target;
import java.lang.annotation.Retention;
import static java.lang.annotation.ElementType.TYPE;
import static java.lang.annotation.RetentionPolicy.RUNTIME;
/**
* Specifies the primary table for the annotated entity. Additional
* tables may be specified using {@link SecondaryTable} or {@link
* SecondaryTables} annotation.
*
* <p> If no <code>Table</code> annotation is specified for an entity
* class, the default values apply.
*
* <pre>
* Example:
*
* @Entity
* @Table(name="CUST", schema="RECORDS")
* public class Customer { ... }
* </pre>
*
* @since 1.0
*/
@Target(TYPE)
@Retention(RUNTIME)
public @interface Table {
/**
* (Optional) The name of the table.
* <p> Defaults to the entity name.
*/
String name() default "";
/** (Optional) The catalog of the table.
* <p> Defaults to the default catalog.
*/
String catalog() default "";
/** (Optional) The schema of the table.
* <p> Defaults to the default schema for user.
*/
String schema() default "";
/**
* (Optional) Unique constraints that are to be placed on
* the table. These are only used if table generation is in
* effect. These constraints apply in addition to any constraints
* specified by the <code>Column</code> and <code>JoinColumn</code>
* annotations and constraints entailed by primary key mappings.
* <p> Defaults to no additional constraints.
*/
UniqueConstraint[] uniqueConstraints() default {};
/**
* (Optional) Indexes for the table. These are only used if
* table generation is in effect. Note that it is not necessary
* to specify an index for a primary key, as the primary key
* index will be created automatically.
*
* @since 2.1
*/
Index[] indexes() default {};
}
- 위에 주석에서 Specifies the primary table for the annotated entity. Additional tables may be specified using SecondaryTable or SecondaryTables annotation. 해당 부분을 번역해보면 아래와 같습니다.
- 어노테이션이 달린 엔티티의 기본 테이블을 지정합니다. 보조 테이블 또는 보조 테이블 어노테이션을 사용하여 추가 테이블을 지정할 수 있습니다.
- 그렇다면 실제 속성들을 살펴보면 아래와 같습니다.
- name: 테이블의 이름이며, 기본값은 Entity의 이름입니다.
- catalog: 테이블의 catalog의 이름이며, default catalog를 디폴트로 사용합니다.
- DB의 catalog란?
- DB의 메타데이터로 데이터에 대한 데이터를 포함한 정보를 구조화하여 저장한 것을 의미합니다.
- 테이블, 인덱스, 뷰, 도메인 등 데이터베이스의 구조와 관련된 객체의 이름, 데이터 유형 및 사이즈, 연관되어 있는지 정보를 제공하게 됩니다.
- DB의 catalog란?
- schema: 테이블의 스키마이며, 사용자의 스키마를 사용하빈다.
- uniqueConstraints: 테이블에 설정할 고유 제약 조건입니다. 테이블 생성이 유효한 경우에만 사용됩니다. 이러한 제약 조건은 Column 및 JoinColumn 주석에 지정된 모든 제약 조건과 기본 키 매핑에 수반되는 제약 조건에 추가로 적용됩니다. 기본값은 추가 제약 조건이 없는 것입니다.
- indexes : 테이블의 인덱스입니다. 테이블 생성이 유효한 경우에만 사용됩니다. 기본 키 인덱스는 자동으로 생성되므로 기본 키에 대한 인덱스를 지정할 필요가 없습니다.
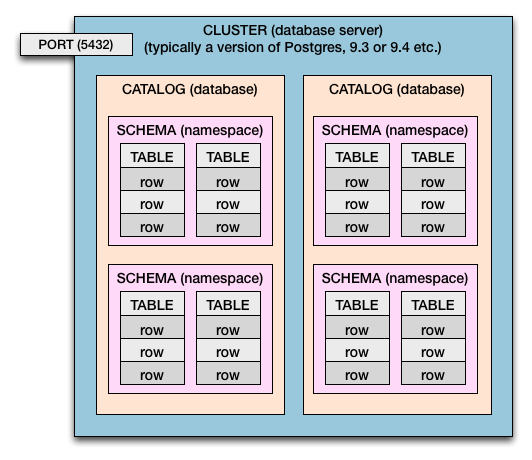
- cf) catalog와 schema의 차이
- Postgres 기준으로 클러스터 > 카탈로그 > 스키마 > 테이블 > 열 및 행 이러한 계층 구조가 있습니다.
- 아래에서 그림을 토대로 알수 있습니다.
그렇다면 name은 어떻게 매핑하는가?
- 원래 주제로 넘어오면, name을 어떻게 매핑하는가?에 대한 코드를 살펴봐야 할거 같습니다.
- 코드를 살펴본 결과 하이버네이트에 EntityBinder#handleClassTable 에 대해서 봐야 할거 같습니다.
private void handleClassTable(InheritanceState inheritanceState, PersistentClass superEntity) {
final String schema;
final String table;
final String catalog;
final UniqueConstraint[] uniqueConstraints;
boolean hasTableAnnotation = annotatedClass.isAnnotationPresent( jakarta.persistence.Table.class );
if ( hasTableAnnotation ) {
final jakarta.persistence.Table tableAnnotation = annotatedClass.getAnnotation( jakarta.persistence.Table.class );
table = tableAnnotation.name();
schema = tableAnnotation.schema();
catalog = tableAnnotation.catalog();
uniqueConstraints = tableAnnotation.uniqueConstraints();
}
else {
//might be no @Table annotation on the annotated class
schema = "";
table = "";
catalog = "";
uniqueConstraints = new UniqueConstraint[0];
}
final InFlightMetadataCollector collector = context.getMetadataCollector();
if ( inheritanceState.hasTable() ) {
createTable( inheritanceState, superEntity, schema, table, catalog, uniqueConstraints, collector );
}
else {
if ( hasTableAnnotation ) {
//TODO: why is this not an error?!
LOG.invalidTableAnnotation( annotatedClass.getName() );
}
if ( inheritanceState.getType() == InheritanceType.SINGLE_TABLE ) {
// we at least need to properly set up the EntityTableXref
bindTableForDiscriminatedSubclass( collector.getEntityTableXref( superEntity.getEntityName() ) );
}
}
}
- @Table 의 어노테이션이 붙어 있는지를 체크하고, 붙어 있지 않다면 default값을 사용하며, 있다면 해당 값들을 사용하게 됩니다.
- 이후에 InFlightMetadataCollector를 가져와 collector로 저장합니다. 그리고 만약 inheritanceState에 table이 있다면 createTable 메서드를 호출합니다.
- InFlightMetadataCollector란 프로그램이 실행되는 중에 데이터베이스 초기화 및 구성 단계에서, 일반적으로 엔티티, 테이블, 열, 링크 등과 같은 다양한 요소에 대한 정보를 수집합니다. 이렇게 수집된 메타데이터는 Hibernate가 다양한 작업을 수행하는 데 필요한 Context 정보를 제공해 일관된 매핑을 유지하고, 엔티티와 DB 테이블 간의 신뢰할 수 있는 매핑을 활용하여 개발자가 애플리케이션에서 DB 작업을 수행하도록 돕습니다
- 위의 메서드에선 Class와 Table에 대한 매핑을 진행한다고 생각해주시면 됩니다.
- 하나 더 메서드를 보면 좋은데 spring-JDBC에 GenericTableMetaDataProvider#locateTableAndProcessMetaData 입니다.
private void locateTableAndProcessMetaData(DatabaseMetaData databaseMetaData,
@Nullable String catalogName, @Nullable String schemaName, @Nullable String tableName) {
Map<String, TableMetaData> tableMeta = new HashMap<>();
ResultSet tables = null;
try {
tables = databaseMetaData.getTables(
catalogNameToUse(catalogName), schemaNameToUse(schemaName), tableNameToUse(tableName), null);
while (tables != null && tables.next()) {
TableMetaData tmd = new TableMetaData(tables.getString("TABLE_CAT"), tables.getString("TABLE_SCHEM"),
tables.getString("TABLE_NAME"));
if (tmd.schemaName() == null) {
tableMeta.put(this.userName != null ? this.userName.toUpperCase() : "", tmd);
}
else {
tableMeta.put(tmd.schemaName().toUpperCase(), tmd);
}
}
}
catch (SQLException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Error while accessing table meta-data results: " + ex.getMessage());
}
}
finally {
JdbcUtils.closeResultSet(tables);
}
if (tableMeta.isEmpty()) {
if (logger.isInfoEnabled()) {
logger.info("Unable to locate table meta-data for '" + tableName + "': column names must be provided");
}
}
else {
processTableColumns(databaseMetaData, findTableMetaData(schemaName, tableName, tableMeta));
}
}
- 여기서 실제 Database의 meta Data를 가져오게 되고, 이때 Tabels의 데이터들을 가져오게 됩니다.
- 마지막으로 아래 메서드에서 validation을 통해 이름이 매칭되는지 체크하게 됩니다.
- AbstractSchemaValidator#validateTables/validateTable
protected abstract void validateTables(
Metadata metadata,
DatabaseInformation databaseInformation,
ExecutionOptions options,
ContributableMatcher contributableInclusionFilter,
Dialect dialect, Namespace namespace);
protected void validateTable(
Table table,
TableInformation tableInformation,
Metadata metadata,
ExecutionOptions options,
Dialect dialect) {
if ( tableInformation == null ) {
throw new SchemaManagementException(
String.format(
"Schema-validation: missing table [%s]",
table.getQualifiedTableName().toString()
)
);
}
for ( Column column : table.getColumns() ) {
final ColumnInformation existingColumn = tableInformation.getColumn( Identifier.toIdentifier( column.getQuotedName() ) );
if ( existingColumn == null ) {
throw new SchemaManagementException(
String.format(
"Schema-validation: missing column [%s] in table [%s]",
column.getName(),
table.getQualifiedTableName()
)
);
}
validateColumnType( table, column, existingColumn, metadata, options, dialect );
}
}
- 실제 Column까지도 다른게 있는지 체크하는 로직이 작성되어 있습니다.
결론
- 단순히 @Table 이라는 어노테이션은 테이블과 엔티티의 이름만 매핑시켜주는 역할만 하는줄 알았지만, 실질적으로 이름이 뿐만 아니라 여러가지 정보를 지정하고, 매핑시켜주는 역할을 하게 됩니다.
- 내부적으로 validate의 로직을 보았을때, 이러한 에러가 발생햇을때 어떤 부분이 문제인지도 알수 있다는 장점이 있는거 같습니다.
- DB의 기능을 잘 알아야, JPA도 잘 쓸수 있는거 같습니다.
728x90
728x90