
ruby에서의 Enumerable#tally란?
서론
예전에 아래와 같은 글을 작성한적이 있다.
해당 글에 아래와 같은 댓글을 누군가 달아주셨다.
루비를 쓰면서 최근 처음보는 Enumerable#tally 를 추천해주셨고 관련된 메서드를 한번 글로 작성하면서 공부해보려고 한다.

해당 글은 Ruby 3.3.6을 기반으로 테스트합니다.
Enumerable#tally
https://ruby-doc.org/3.3.6/Enumerable.html#method-i-tally
module Enumerable - RDoc Documentation
each_entry(*args) {|element| ... } → self click to toggle source each_entry(*args) → enumerator Calls the given block with each element, converting multiple values from yield to an array; returns self: a = [] (1..4).each_entry {|element| a.push(element
ruby-doc.org
해당 문서를 보면, 동일한 요소의 개수를 포함하는 해시를 반환한다고 되어 있습니다.
배열 내에 있는 값들을 자동으로 갯수를 셀수 있는 것이다.
이전에 썻던 글에서는 each_with_object 를 통해 비지니스 로직처럼 작성했지만 루비에서 자체적으로 해준다고 느껴지는 함수이다.
ruby 2.7에서부터 도입된 메서드로 간결함이 장점이라고 느껴진다.
arr = [1, 1, 1, 2, 3, 3, 4, 4, 4, 4, 4, 4, 5, 5, 5, 5, 5]
counters = arr.tally
puts counters => {1=>3, 2=>1, 3=>2, 4=>6, 5=>5}*
간다한 예제코드를 보면 이런식으로 되어 있다.
장점은 배열 전체를 한번만 순회한다는 점이다.
그렇다면 여기서 질문이 생긴다. each_with_index와 tally는 대체 어떤 차이가 있는걸까?
내부적으로 tally는 어떻게 되어 있는것인가?
GPT를 활용해서 공부해보려고 한다.
tally의 내부 코드 (C 구현)
Ruby의 소스코드에 따르면, tally는 대략 다음과 같은 구조를 가집니다:
VALUE
enum_tally(VALUE obj)
{
VALUE hash = rb_hash_new(); // 빈 해시 생성
RETURN_SIZED_ENUMERATOR(obj, 0, 0, enum_size); // 열거자를 반환할 수 있는 Enumerator 생성
rb_block_call(obj, id_each, 0, 0, tally_i, hash); // 블록을 순회하며 요소 카운트
return hash; // 카운트 결과 반환
}
static VALUE
tally_i(VALUE key, VALUE hash)
{
VALUE count;
// 해시에서 현재 키에 해당하는 값 조회
count = rb_hash_lookup2(hash, key, INT2FIX(0)); // 기본값은 0
rb_hash_aset(hash, key, rb_int_plus(count, INT2FIX(1))); // 카운트 증가
return Qnil;
}
주요 동작 원리
해시 초기화: rb_hash_new()를 통해 빈 해시를 생성합니다.
순회 및 카운트: rb_block_call을 사용해 각 요소를 순회하면서, 해당 요소를 키로 사용하는 해시에 값을 증가시킵니다.
rb_hash_lookup2는 키가 없을 경우 기본값 0을 반환합니다.
rb_int_plus를 사용해 기존 값에 1을 더하고 해시에 저장합니다.
결과 반환: 모든 요소를 순회한 후, 최종 해시를 반환합니다.
each_with_object와의 차이점
언어 레벨
tally는 Ruby의 C 레벨에서 동작하므로 더 효율적입니다.
each_with_object는 Ruby 코드로 작성된 메서드이므로 인터프리터를 통해 실행됩니다.
최적화
tally는 C에서 직접적으로 메모리를 다루고, 불필요한 객체 생성 및 해시 접근을 최소화합니다.
each_with_object는 Ruby 레벨에서 블록을 호출하고, 각 호출 시 Ruby 객체 간의 메서드 호출 오버헤드가 발생합니다.
가독성 및 간결성
tally는 호출만으로 배열의 요소 개수를 구할 수 있으므로 코드가 더 간결합니다.
each_with_object는 블록을 작성해야 하므로 약간의 코드 작성 부담이 있습니다.
기본값 처리
tally는 내부적으로 rb_hash_lookup2를 사용하여 기본값을 처리합니다.
each_with_object는 명시적으로 Hash.new(0)을 사용해 기본값을 설정해야 합니다.
성능
- tally는 C 구현 덕분에 더 빠릅니다. 특히 큰 배열을 처리할 때 성능 차이가 더 커집니다.
- each_with_object는 Ruby 코드이므로 상대적으로 느립니다.
벤치마킹
require 'benchmark'
arr = Array.new(10_000) { rand(1..5) }
Benchmark.bm do |x|
x.report('Enumerable#tally') do
1_000.times { arr.tally }
end
x.report('each_with_object') do
1_000.times do
arr.each_with_object(Hash.new(0)) { |number, hash| hash[number] += 1 }
end
end
x.report('basic count') do
1_000.times do
[1, 2, 3, 4, 5].each { |n| arr.count(n) }
end
end
end
해당 코드를 통해 tally, count, each_with_object를 진행해보려고 한다.
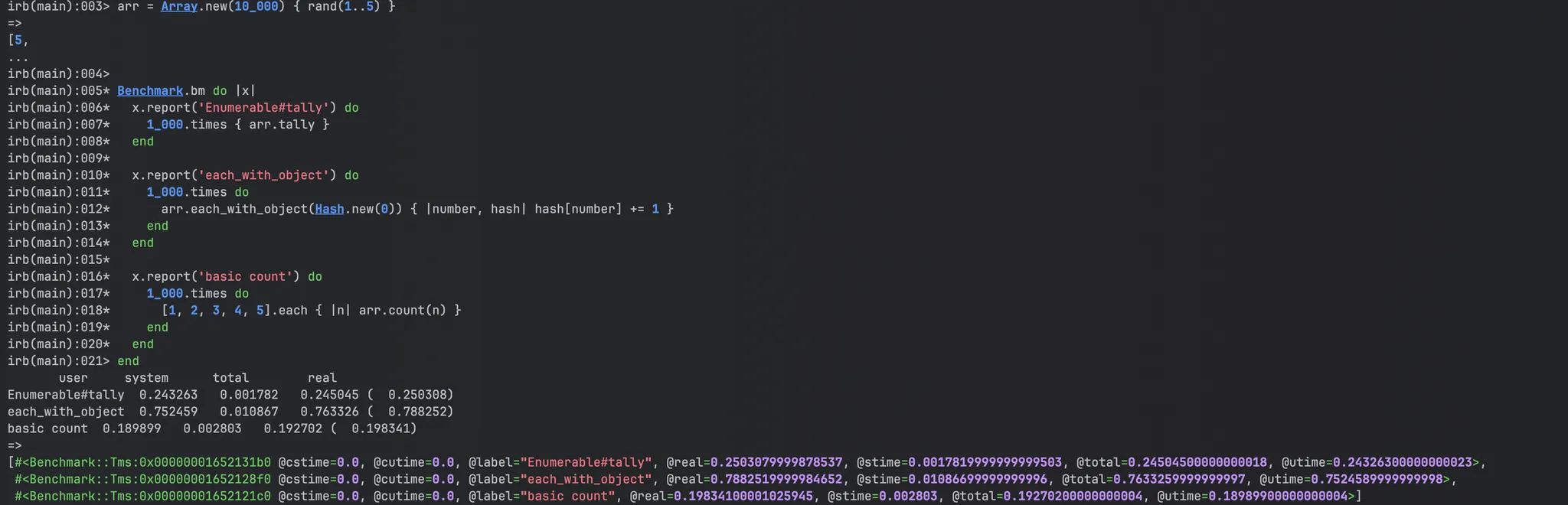
한번의 banchmark를 본다면 count가 가장 빠르며, 그다음은 Enumable#tally, 그 다음은 each_with_object이다.
근데 해당 코드는 단순히 출력의 목적을 둔것이기 떄문에 한번 Hash를 return해야 하는 케이스를 기반해서 테스트를 해보려고 한다.
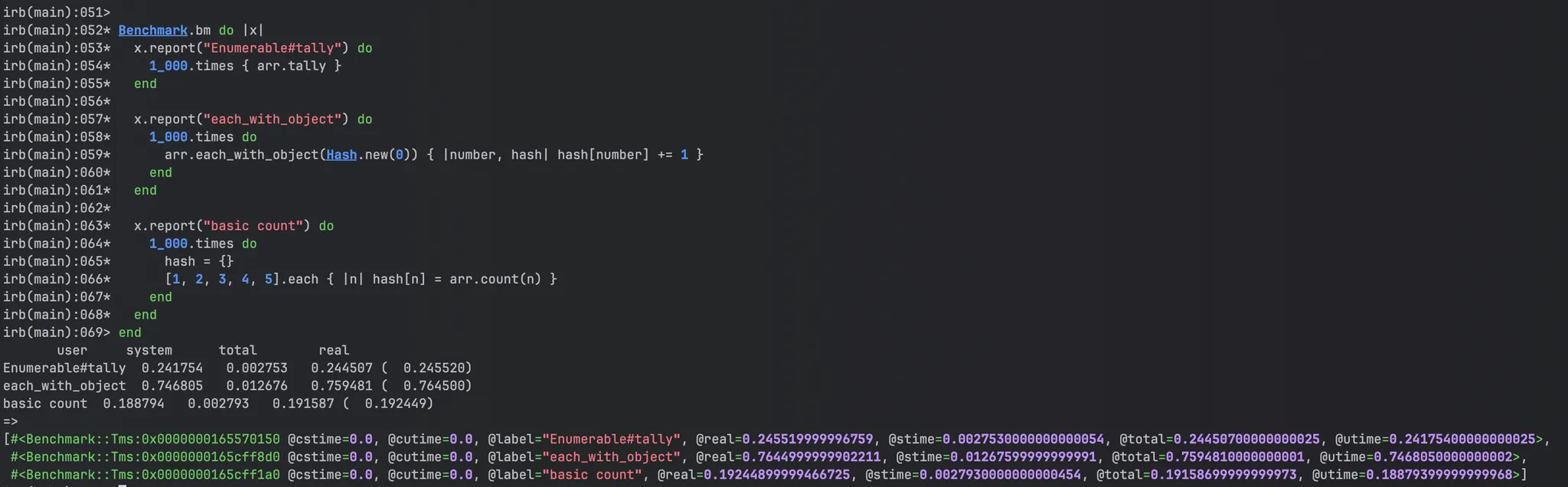
arr = Array.new(10_000) { rand(1..5) }
Benchmark.bm do |x|
x.report("Enumerable#tally") do
1_000.times { arr.tally }
end
x.report("each_with_object") do
1_000.times do
arr.each_with_object(Hash.new(0)) { |number, hash| hash[number] += 1 }
end
end
x.report("basic count") do
1_000.times do
hash = {}
[1, 2, 3, 4, 5].each { |n| hash[n] = arr.count(n) }
end
end
end
이렇게 해도 basic_count가 제일 빠른걸 확인할 수 있다.
결론
코드의 간결함을 지키기 위해서는 tally가 가장 좋은거 같다.
그러나 성능이 중요하다면 basic count를 이용하는게 가장 효과적인것인거 같다.