Django Performance Improvements - Part 1: Database Optimizations(Django 성능 향상 - Part1: 데이터베이스 최적화)
Django 프로젝트에서 최적화의 주요 목표는 시스템 리소스를 최대한 활용하여 데이터베이스 쿼리를 빠르게 수행하여 프로젝트가 실행하게 하는 것입니다. 적절히 최적화된 데이터베이스로 응답시간을 줄여 더 나은 사용자 경험을 제공합니다.
이 4개의 시리즈에선 Django 애플리케이션의 다양한 영역에서 최적화 하는 방법을 배우게 됩니다.
이 파트에선 데이터베이스를 최적화하여 Django 애플리케이션의 속도를 향상시키는 것에 중점을 둡니다.
쿼리를 이해하기
QuerySet이 어떻게 동작 하는지 이해하면 더 좋은 코드를 작성할 수 있습니다. 최적화 하기 전에 아래 개념을 먼저 이해해 봅시다.
- QuerySet은 lazy하다.
- 원하는 만큼 많은 쿼리를 작성할 수 있지만, Django는 쿼리가 실행될때만 데이터베이스에 Query를 보냅니다.
- 반환해야 하는 값의 갯수를 limit을 이용해 지정하세요.
- Django에서 iteration, slicing, caching, len()과 count()과 같은 파이썬 메소드등으로 Queryset을 사용할 수 있으므로 이를 최대한 활용해야 합니다.
- Django는 모든 QuerySet에 캐싱을 수행해 데이터베이스 접근을 최소화 합니다. 캐싱이 동작하는 방식을 이해하고 있다면 더 효율적인 코드를 작성할 수 있습니다.
- 필요한 것만 검색해야 한다.
- 차후에 사용할 것 같다면 한번에 검색을 해야 한다.
- 항상 데이터베이스 작업은 Python이 아니라 Query를 이용해서 수행하세요.
Query 최적화
데이터베이스는 애플리케이션의 핵심입니다. 믿음과 달리 복잡성이 항상 효율성을 보장하는 것이 아닙니다. Postgresql은 오픈소스 특성으로 Django 프로젝트에서 선호되는 데이터베이스입니다. 복잡한 쿼리도 잘 수행합니다. Django 애플리케이션에서 쿼리를 최적화 하기 위해 데이터베이스 최적화를 해야 하며, 다음과 같은 영역을 다루도록 하겠습니다.
- database indexing(인덱싱)
- Caching(캐싱)
- select related vs. fetch related
- bulk method(일괄 메소드)
- RawSql
- Foreign keys(외래키)
1. Database indexing
데이터베이스의 인덱싱은 데이터베이스에서 레코드를 검색할때 속도 향상을 위해 사용되는 기술입니다. 많은 양의 데이터를 가진 데이터베이스로 작업할 때 인덱싱은 앱을 더 빠르게 만들기 위해 무조건 사용해야 하는 방법입니다.
애플리케이션이 중요해지면, 속도가 느려질수 있으며 요청한 데이터를 얻는데 상당 시간 걸리기 때문에 사용자는 바로 알아챕니다. 이를 설명하기 위해 아래의 전자 상거래 예시 모델을 사용합니다.
class Product(models.Model):
product_name = models.CharField(max_length=50)
description = models.TextField()
price = models.DecimalField(decimal_places=2, max_digits=8)
image = models.ImageField()
def __str(self):
return self.product_name
class Order(models.Model):
customer_id = models.ForeignKey(User, on_delete=models.CASCADE)
product_id = models.ForeignKey(Product, on_delete=models.CASCADE)
quantity = models.IntegerField()
shipping_fee = models.DecimalField(deciaml_places=2, max_digits=4)
dicount = models.DecimalField(deciaml_places=2, max_digits=4, default=0)
total_cost = models.DecimalField(deciaml_places=2, max_digits=10)
date_ordered = models.DateTimeField(default = timezon.now)
데이터베이스의 데이터가 많아 짐에 따라 데이터 검색 속도도 상당한 시간이 걸리게 됩니다. 예를들어 컬럼의 검색 속도를 향상 시키기 위해 price column에 인덱스를 적용한다고 가정해봅시다.
price = models.DecimalField(decimal_places= 2,max_digits=8,db_index=True)인덱스 적용 후 인덱스가 생성되도록 마이그레이션을 실행해야 합니다.
테이블에 row(데이터)가 많을 경우 인덱스를 생성하는데 시간이 더 많이 걸립니다. 두 필드에 대해 단일 인덱스를 만들 수 있습니다.
class Product(models.Model):
name = models.CharField(max_length=120)
description = models.CharField(max_length=255)
price = models.IntegerField(default = 0)
class Meta:
indexes = [
["name", "price"]
]2. Caching
데이터베이스의 캐싱은 빠른 응답을 위해 최고의 접근법입니다. 데이터베이스에 대한 호출을 최소화해 데이터베이스의 과부하를 방지합니다. 표준 캐시 구조는 아래와 같습니다.
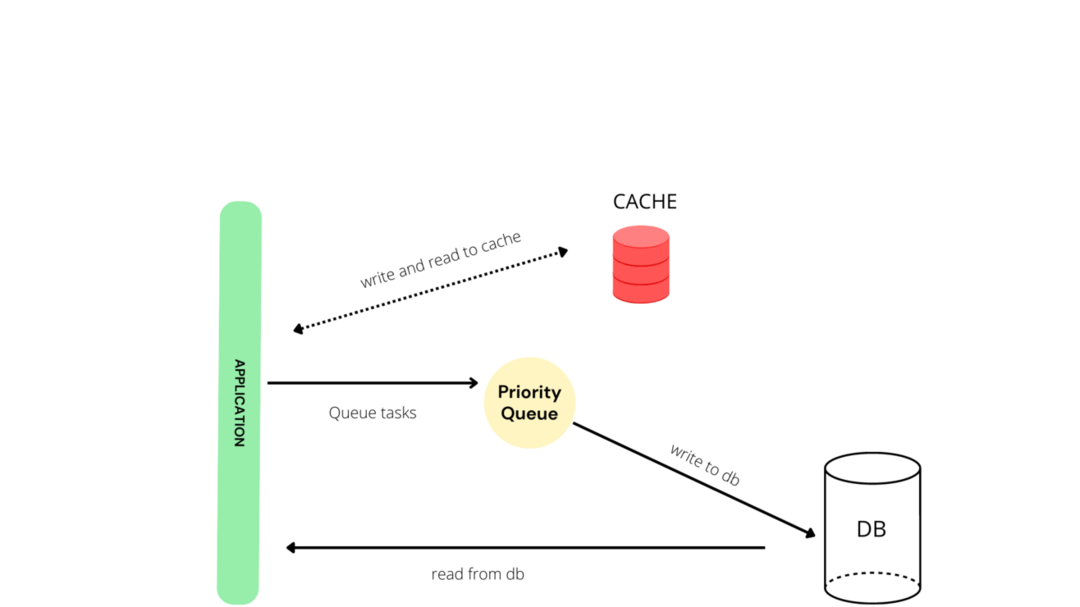
Django는 쿼리가 여러번 실행되지 않도록 Memcached, Redis와 같은 다양한 캐싱 방법을 사용할 수 있도록 하나의 캐싱 매커니즘을 제공합니다.
Memcached는 millisecond 미만으로 캐시된 결과를 반환하도록 보장하는 간단하지만 강력한 오픈소스 인메모리 시스템입니다. Memcached는 사용하기 쉽고 확장 가능합니다.
반면에 Redis는 Memcached와 동일한 기능을 제공하는 오픈 소스 캐싱 시스템입니다. 대부분 오프라인 애플리케이션은 이미 캐시된 데이터를 사용함으로 대부분의 요청이 데이터베이스에 도달하지도 않습니다.
사용자 세션은 Django 애플리케이션의 캐시에 저장되어야 하며, Redis는 데이터를 디스크를 유지하기 떄문에 로그인한 사용자의 모든 세션은 데이터베이스에 가지 않고 캐시된 데이터를 사용합니다. Redis 데이터베이스를 사용하기 위해 pip를 통해 redis를 설치하면 됩니다.
pip install redisredis가 설치되면 settings.py에 아래 코드를 추가합니다.
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.redis.RedisCache',
'LOCATION': 'redis://127.0.0.1:6379',
}
}Memcached 및 Redis를 사용해 사용자 인증 토큰을 저장할 수 있습니다. 로그인한 모든 사용자에게 토큰을 제공해야 함으로 이 작업은 데이터베이스에 높은 오버헤드를 발생시킬 수 있습니다. 캐시에서 토큰을 가져온다면 데이터베이스 성능은 훨씬 빨라질 것입니다.
3. Select related Vs. Prefetch related
Django는 select_related, prefetch_related를 통해 Queryset를 최적화 할 수 있도록 메소드를 제공합니다. 이러한 두 메서드는 데이터베이스에서 발생하는 쿼리의 수를 줄여줍니다. 예를들면 아래와 같이 2개의 테이블의 모델이 있다고 해봅시다.
class Person(models.Model):
first_name = models.CharField(max_length=100, null=False, blank=False)
last_name = models.CharField(max_length=100, null=False, blank=False)
email = models.EmailField()
def __str__(self):
return self.first_name + self.last_name
class Tweet(models.Model):
subject = models.CharField(max_length=100, null=False, blank=False)
created_at = models.DateTimeField(default=timezone.now)
owner = models.ForeignKey(Person.on_delete=models.CASCADE)
def __str__(self):
return self.subjectperson 테이블은 Tweet 테이블과 1:다 관계를 가지고 있습니다. 즉, 한 사람은 많은 트윗을 가질 수 있지만 트윗은 한 사람에게만 속할 수 있습니다. 데이터베이스에 있는 모든 트윗의 세부 정보를 찾으려면 먼저 모든 트윗을 가져옵니다. first_name 및 last_name의 값을 가져오려면 다음과 같이 추가 쿼리를 수행해야 합니다.
> from django.db import connection
> from app.models import Person, Tweet
> tweets = Tweet.objects.all()
> tweet_details = [tweet.owner first_name for tweet in tweets]
> tweets
<QuerySet [<Tweet: what's your favorite Programming Language>, <Tweet: Good morning>, <Tweet: Good afternoon>, <Tweet: Good morning>, <Tweet: Good evening>]>
> tweet_details
['Esther', 'Esther', 'Esther', 'Esther', 'Mike', 'Nina', 'Paul', 'Mike']
> len(connection.queries)
9결과적으로 9개의 쿼리가 생성되게 됩니다.
select_related
select_related를 사용하면 one-to-many, one-to-one 관계에 대한 모든 관련된 객체들을 단일 쿼리로 반환 받을수 있습니다. select_related는 쿼리 실행 시 추가 관련 다른 객체 데이터를 검색하기 위해 외래 키 관계에 사용되는 쿼리입니다.
select_related로 인해 쿼리가 더 복잡해지지만 얻은 데이터는 캐싱됩니다. 따라서 얻은 데이터를 조작하는데 추가 쿼리가 필요하지 않습니다.
selected_related를 사용해 동일한 쿼리를 수행해보도록 하겠습니다.
queryset = Tweet.objects.select_related('owner').all()위의 코드는 모든 Tweet, Person 데이터를 한번에 가져오는 단일 쿼리만 생성되게 됩니다.
> queryset = Tweet.objects.select_releated('owner').all()
> queryset
<QuerySet [<Tweet: what's your favorite Programming Language>, <Tweet: Good morning>, <Tweet: Good afternoon>, <Tweet: Good morning>, <Tweet: Good evening>]>
> len(connection.queries)
1
> queryset_details = [tweet.owner first_name for tweet in tweets]
> queryset_details
['Esther', 'Esther', 'Esther', 'Esther', 'Mike', 'Nina', 'Paul', 'Mike']
> len(connection.queries)
1prefetch_related
반면에 prefetch_related는 many-to-many, many-to-one 관계에 사용합니다. 쿼리에 특별한 필터나 모든 모델을 단일 쿼리로 찾아올 수 있습니다.
예를들어 아래와 같은 모델이 있다고 해봅시다.
class Actor(models.Model):
first_name = models.CharField(max_length=255, null=False, blank=False)
last_name = models.CharField(max_length=255, null=False, blank=False)
def __str__(self):
return self.first_name + self.last_name
class Movie(models.Model):
title = models.CharField(max_length=255, null=False, blank=False)
actors = models.ManyToManyField(Actor)
def __str__(self):
return self.title아래에서 모든 영화와 관련 배우들을 가져올 수 있습니다.
> movies = Movie.objects.all()
> actors = [movie.actors.all() for movie in movies]
> actors[0]
> QuerySet [<Actor: Nina>, <Actor: Paul>, <Actor: Ian>, <Actor: Catherine>]>
> len(connection.queries)
4
> actors[1]
<QuerySet [Actor: Nina>]>
> len(connection.queries)
5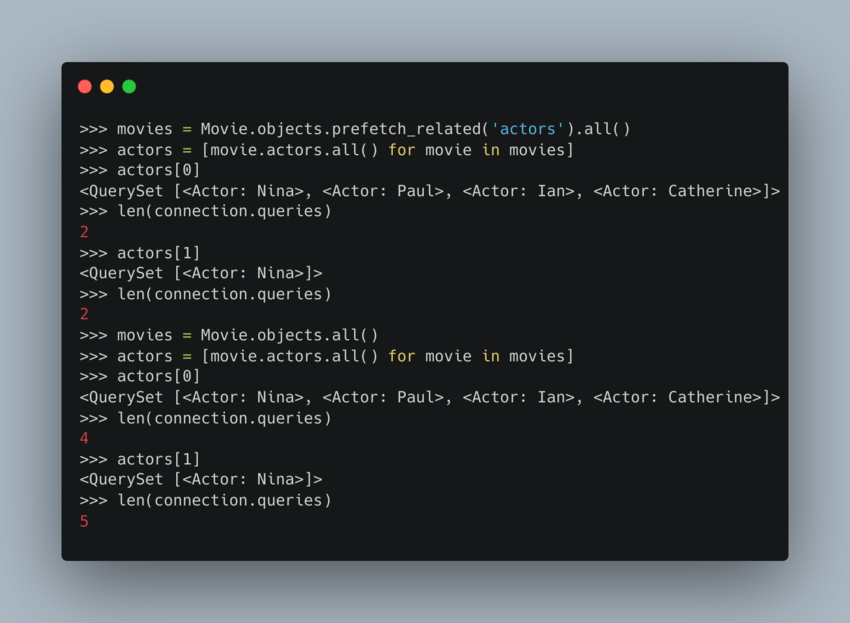
위에서 볼 수 있듯이, 반복을 할때마다 추가 쿼리가 생기게 됩니다.
이제 prefetch를 이용해 같은 쿼리를 실행해보도록 하겠습니다.
> movies = Movie.objects.prefetch_related('actors').all()
> actors = [movie.actors.all() for movie in movies]
> actors[0]
> QuerySet [<Actor: Nina>, <Actor: Paul>, <Actor: Ian>, <Actor: Catherine>]>
> len(connection.queries)
2
> actors[1]
<QuerySet [Actor: Nina>]>
> len(connection.queries)
2위에서 볼 수 있듯이 쿼리의 갯수는 2개이며 첫번째 쿼리에서 데이터베이스의 모든 영화를 가져오고 두 번째, 세 번째 요청에서는 단일 쿼리만 발생하게 됩니다.
4. bulk method
일괄 처리는 쿼리를 검색하는 또 다른 성능 방법입니다.
데이터베이스에 여러 레코드를 추가할때 가장 효과적인 방법은 모든 개체를 한번에 만드는 것입니다. Django는 bulk_create() 를 제공합니다. 각 인스턴스를 한번에 생성 한 뒤 데이터베이스에 과부하를 주는 대신 모든 인스턴스를 커밋해 단일 저장 쿼리를 수행하게 됩니다.
Actor.objects.bulk_create([
Actor(first_name='Nina', second_name='Dobrev'),
Actor(first_name='Paul', second_name='Wesley'),
Actor(first_name='Ian', second_name='Somerholder'),
]또한 bulk_create and bulk_update()를 할 수 있습니다. 예를들어 특정 값으로 업데이트를 해야 한다고 가정하면 가장 효율적인 방법은bulk_update 를 사용하는 것입니다.
Model.objects.filter(name= 'name').update(name='someothername')5. RawSql
Django는 높은 수준의 쿼리 매커니즘을 제공하기 때문에 RawSQL은 권장되지 않습니다.
Django ORM을 이용해 모든 기능들을 처리할 수 있지만 떄로 필요할 수도 있습니다. Python이 아닌 데이터베이스에서 SQL 쿼리를 수행하면 성능이 더 빨라질 수 있습니다. 그러나 RawSQL은 최후의 수단으로 사용해야 합니다.
6. Foreign keys(외래키)
외래 키를 사용해 데이터베이스에 추가 부담 없이 데이터를 얻을 수 있습니다. 예를들어 트윗의 소유자를 얻기 위해 가장 효율적인 방법은 아래와 같습니다.
person = Person.objects.get(tweet__id =1)데이터베이스 작업 모니터링
프로덕션에선 데이터베이스 작업을 모니터링 하는것이 좋습니다. 이를 통해 데이터베이스에서 실행된 쿼리와 발생한 오류를 확인할 수 있습니다. Postgres 또는 Django 로그를 수시로 확인해 이를 수행할 수 있습니다. 이를 쉽게 하기 위해 Sentry를 사용할 수 있습니다.
Sentry는 Django 애필르케이션에서 데이터베이스 작업을 실시간으로 모니터링하기 위해 대시보드를 제공합니다. 데이터베이스와 관련된 오류를 실시간으로 확인하고 사용자가 발생하기 전에 해결이 가능합니다.
디버거가 없기 때문에 프로덕션에서의 오류를 인지하기 어려울 수 있지만, Sentry는 데이터베이스의 모든 오류를 볼 수 있도록 해 이 문제를 해결하고 있습니다.
시작을 하기 위해 여기서 Sentry 계정을 만들어 주세요. 사용중인 기술스택을 선택 창에서 Django를 선택해 프로젝트를 만들기(create Project)를 클릭합니다.
다음에 pip를 통해 Sentry를 설치합니다.
pip install --upgrade sentry-sdk마지막 단계로 settings.py에 공개키를 포함해 아래오 ㅏ같이 코드를 추가하면 됩니다.
import sentry_sdk
from sentry_sdk.integrations.django import DjangoIntegration
sentry_sdk.init(
dsn="https://examplePublicKey@o0.ingest.sentry.io/0",
integrations=[DjangoIntegration()],
# Set traces_sample_rate to 1.0 to capture 100%
# of transactions for performance monitoring.
# We recommend adjusting this value in production,
traces_sample_rate=1.0,
# If you wish to associate users to errors (assuming you are using
# django.contrib.auth) you may enable sending PII data.
send_default_pii=True,
# By default the SDK will try to use the SENTRY_RELEASE
# environment variable, or infer a git commit
# SHA as release, however you may want to set
# something more human-readable.
# release="myapp@1.0.0",
)Sentry를 이용해 애플리케이션을 모니터링 할 준비가 모두 되었습니다.
데이터베이스에 관련 오류를 생성해 Snetry가 원인을 보여줄 수 있는지 봅시다. 데이터베이스의 존재하지 않은 제품을 검색해 발생하는 샘플 오류입니다.
이 오류는 아래와 같이 Sentry 대시보드에 나타납니다.
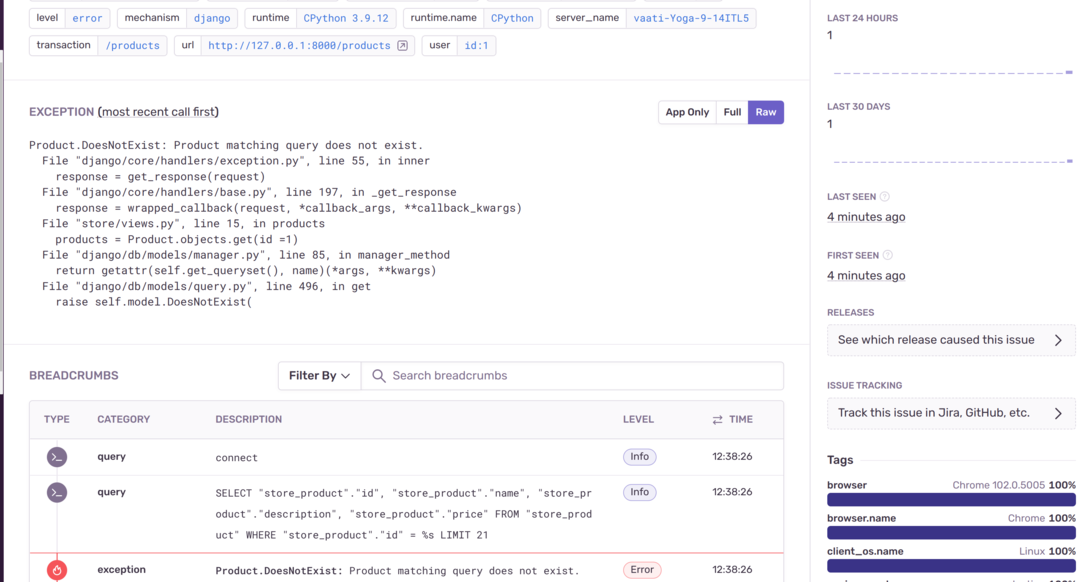
Django는 데이터베이스를 모니터링 하는 Django Debug toolbar를 제공하여 요청 및 응답에 대한 프로세스를 실시간으로 확인할 수 있습니다. 또한 각 응답이 데이터베이스에서 데이터를 가져오는 시간을 확인할 수 있습니다.
Django debug toolbar를 pip로 설치하면 됩니다.
python -m pip install django-debug-toolbarDjango debug toolbar를 설치한 후엔 Django project에 설정을 해주면 됩니다.
아래 이미지는 Django debug toolbar가 동작하는 모습을 보여줍니다.
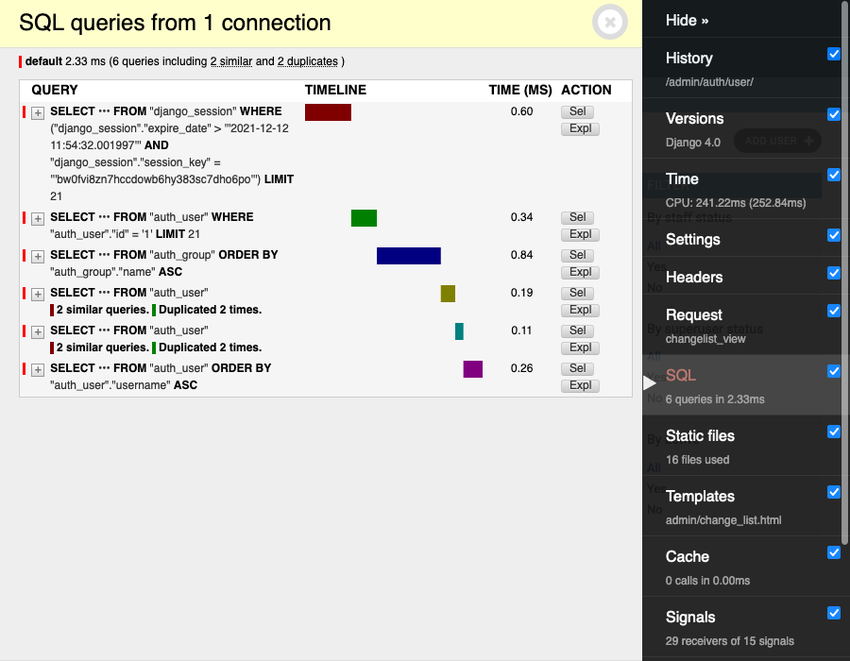
Django debug toolbar를 사용할때 단점은 페이지를 랜더할때 오버헤드가 추가됨으로 프로덕션에서 설정하는데 적절하지 않습니다. Sentry는 버그를 파악하고 데이터베이스에 대한 자세한 추적이 가능하도록 데이터를 제공하여 문제를 해결할 수 있습니다.
'Backend > Django' 카테고리의 다른 글
Django Performance Improvements - Part 1: Database Optimizations(Django 성능 향상 - Part1: 데이터베이스 최적화)
Django 프로젝트에서 최적화의 주요 목표는 시스템 리소스를 최대한 활용하여 데이터베이스 쿼리를 빠르게 수행하여 프로젝트가 실행하게 하는 것입니다. 적절히 최적화된 데이터베이스로 응답시간을 줄여 더 나은 사용자 경험을 제공합니다.
이 4개의 시리즈에선 Django 애플리케이션의 다양한 영역에서 최적화 하는 방법을 배우게 됩니다.
이 파트에선 데이터베이스를 최적화하여 Django 애플리케이션의 속도를 향상시키는 것에 중점을 둡니다.
쿼리를 이해하기
QuerySet이 어떻게 동작 하는지 이해하면 더 좋은 코드를 작성할 수 있습니다. 최적화 하기 전에 아래 개념을 먼저 이해해 봅시다.
- QuerySet은 lazy하다.
- 원하는 만큼 많은 쿼리를 작성할 수 있지만, Django는 쿼리가 실행될때만 데이터베이스에 Query를 보냅니다.
- 반환해야 하는 값의 갯수를 limit을 이용해 지정하세요.
- Django에서 iteration, slicing, caching, len()과 count()과 같은 파이썬 메소드등으로 Queryset을 사용할 수 있으므로 이를 최대한 활용해야 합니다.
- Django는 모든 QuerySet에 캐싱을 수행해 데이터베이스 접근을 최소화 합니다. 캐싱이 동작하는 방식을 이해하고 있다면 더 효율적인 코드를 작성할 수 있습니다.
- 필요한 것만 검색해야 한다.
- 차후에 사용할 것 같다면 한번에 검색을 해야 한다.
- 항상 데이터베이스 작업은 Python이 아니라 Query를 이용해서 수행하세요.
Query 최적화
데이터베이스는 애플리케이션의 핵심입니다. 믿음과 달리 복잡성이 항상 효율성을 보장하는 것이 아닙니다. Postgresql은 오픈소스 특성으로 Django 프로젝트에서 선호되는 데이터베이스입니다. 복잡한 쿼리도 잘 수행합니다. Django 애플리케이션에서 쿼리를 최적화 하기 위해 데이터베이스 최적화를 해야 하며, 다음과 같은 영역을 다루도록 하겠습니다.
- database indexing(인덱싱)
- Caching(캐싱)
- select related vs. fetch related
- bulk method(일괄 메소드)
- RawSql
- Foreign keys(외래키)
1. Database indexing
데이터베이스의 인덱싱은 데이터베이스에서 레코드를 검색할때 속도 향상을 위해 사용되는 기술입니다. 많은 양의 데이터를 가진 데이터베이스로 작업할 때 인덱싱은 앱을 더 빠르게 만들기 위해 무조건 사용해야 하는 방법입니다.
애플리케이션이 중요해지면, 속도가 느려질수 있으며 요청한 데이터를 얻는데 상당 시간 걸리기 때문에 사용자는 바로 알아챕니다. 이를 설명하기 위해 아래의 전자 상거래 예시 모델을 사용합니다.
class Product(models.Model):
product_name = models.CharField(max_length=50)
description = models.TextField()
price = models.DecimalField(decimal_places=2, max_digits=8)
image = models.ImageField()
def __str(self):
return self.product_name
class Order(models.Model):
customer_id = models.ForeignKey(User, on_delete=models.CASCADE)
product_id = models.ForeignKey(Product, on_delete=models.CASCADE)
quantity = models.IntegerField()
shipping_fee = models.DecimalField(deciaml_places=2, max_digits=4)
dicount = models.DecimalField(deciaml_places=2, max_digits=4, default=0)
total_cost = models.DecimalField(deciaml_places=2, max_digits=10)
date_ordered = models.DateTimeField(default = timezon.now)
데이터베이스의 데이터가 많아 짐에 따라 데이터 검색 속도도 상당한 시간이 걸리게 됩니다. 예를들어 컬럼의 검색 속도를 향상 시키기 위해 price column에 인덱스를 적용한다고 가정해봅시다.
price = models.DecimalField(decimal_places= 2,max_digits=8,db_index=True)인덱스 적용 후 인덱스가 생성되도록 마이그레이션을 실행해야 합니다.
테이블에 row(데이터)가 많을 경우 인덱스를 생성하는데 시간이 더 많이 걸립니다. 두 필드에 대해 단일 인덱스를 만들 수 있습니다.
class Product(models.Model):
name = models.CharField(max_length=120)
description = models.CharField(max_length=255)
price = models.IntegerField(default = 0)
class Meta:
indexes = [
["name", "price"]
]2. Caching
데이터베이스의 캐싱은 빠른 응답을 위해 최고의 접근법입니다. 데이터베이스에 대한 호출을 최소화해 데이터베이스의 과부하를 방지합니다. 표준 캐시 구조는 아래와 같습니다.
Django는 쿼리가 여러번 실행되지 않도록 Memcached, Redis와 같은 다양한 캐싱 방법을 사용할 수 있도록 하나의 캐싱 매커니즘을 제공합니다.
Memcached는 millisecond 미만으로 캐시된 결과를 반환하도록 보장하는 간단하지만 강력한 오픈소스 인메모리 시스템입니다. Memcached는 사용하기 쉽고 확장 가능합니다.
반면에 Redis는 Memcached와 동일한 기능을 제공하는 오픈 소스 캐싱 시스템입니다. 대부분 오프라인 애플리케이션은 이미 캐시된 데이터를 사용함으로 대부분의 요청이 데이터베이스에 도달하지도 않습니다.
사용자 세션은 Django 애플리케이션의 캐시에 저장되어야 하며, Redis는 데이터를 디스크를 유지하기 떄문에 로그인한 사용자의 모든 세션은 데이터베이스에 가지 않고 캐시된 데이터를 사용합니다. Redis 데이터베이스를 사용하기 위해 pip를 통해 redis를 설치하면 됩니다.
pip install redisredis가 설치되면 settings.py에 아래 코드를 추가합니다.
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.redis.RedisCache',
'LOCATION': 'redis://127.0.0.1:6379',
}
}Memcached 및 Redis를 사용해 사용자 인증 토큰을 저장할 수 있습니다. 로그인한 모든 사용자에게 토큰을 제공해야 함으로 이 작업은 데이터베이스에 높은 오버헤드를 발생시킬 수 있습니다. 캐시에서 토큰을 가져온다면 데이터베이스 성능은 훨씬 빨라질 것입니다.
3. Select related Vs. Prefetch related
Django는 select_related, prefetch_related를 통해 Queryset를 최적화 할 수 있도록 메소드를 제공합니다. 이러한 두 메서드는 데이터베이스에서 발생하는 쿼리의 수를 줄여줍니다. 예를들면 아래와 같이 2개의 테이블의 모델이 있다고 해봅시다.
class Person(models.Model):
first_name = models.CharField(max_length=100, null=False, blank=False)
last_name = models.CharField(max_length=100, null=False, blank=False)
email = models.EmailField()
def __str__(self):
return self.first_name + self.last_name
class Tweet(models.Model):
subject = models.CharField(max_length=100, null=False, blank=False)
created_at = models.DateTimeField(default=timezone.now)
owner = models.ForeignKey(Person.on_delete=models.CASCADE)
def __str__(self):
return self.subjectperson 테이블은 Tweet 테이블과 1:다 관계를 가지고 있습니다. 즉, 한 사람은 많은 트윗을 가질 수 있지만 트윗은 한 사람에게만 속할 수 있습니다. 데이터베이스에 있는 모든 트윗의 세부 정보를 찾으려면 먼저 모든 트윗을 가져옵니다. first_name 및 last_name의 값을 가져오려면 다음과 같이 추가 쿼리를 수행해야 합니다.
> from django.db import connection
> from app.models import Person, Tweet
> tweets = Tweet.objects.all()
> tweet_details = [tweet.owner first_name for tweet in tweets]
> tweets
<QuerySet [<Tweet: what's your favorite Programming Language>, <Tweet: Good morning>, <Tweet: Good afternoon>, <Tweet: Good morning>, <Tweet: Good evening>]>
> tweet_details
['Esther', 'Esther', 'Esther', 'Esther', 'Mike', 'Nina', 'Paul', 'Mike']
> len(connection.queries)
9결과적으로 9개의 쿼리가 생성되게 됩니다.
select_related
select_related를 사용하면 one-to-many, one-to-one 관계에 대한 모든 관련된 객체들을 단일 쿼리로 반환 받을수 있습니다. select_related는 쿼리 실행 시 추가 관련 다른 객체 데이터를 검색하기 위해 외래 키 관계에 사용되는 쿼리입니다.
select_related로 인해 쿼리가 더 복잡해지지만 얻은 데이터는 캐싱됩니다. 따라서 얻은 데이터를 조작하는데 추가 쿼리가 필요하지 않습니다.
selected_related를 사용해 동일한 쿼리를 수행해보도록 하겠습니다.
queryset = Tweet.objects.select_related('owner').all()위의 코드는 모든 Tweet, Person 데이터를 한번에 가져오는 단일 쿼리만 생성되게 됩니다.
> queryset = Tweet.objects.select_releated('owner').all()
> queryset
<QuerySet [<Tweet: what's your favorite Programming Language>, <Tweet: Good morning>, <Tweet: Good afternoon>, <Tweet: Good morning>, <Tweet: Good evening>]>
> len(connection.queries)
1
> queryset_details = [tweet.owner first_name for tweet in tweets]
> queryset_details
['Esther', 'Esther', 'Esther', 'Esther', 'Mike', 'Nina', 'Paul', 'Mike']
> len(connection.queries)
1prefetch_related
반면에 prefetch_related는 many-to-many, many-to-one 관계에 사용합니다. 쿼리에 특별한 필터나 모든 모델을 단일 쿼리로 찾아올 수 있습니다.
예를들어 아래와 같은 모델이 있다고 해봅시다.
class Actor(models.Model):
first_name = models.CharField(max_length=255, null=False, blank=False)
last_name = models.CharField(max_length=255, null=False, blank=False)
def __str__(self):
return self.first_name + self.last_name
class Movie(models.Model):
title = models.CharField(max_length=255, null=False, blank=False)
actors = models.ManyToManyField(Actor)
def __str__(self):
return self.title아래에서 모든 영화와 관련 배우들을 가져올 수 있습니다.
> movies = Movie.objects.all()
> actors = [movie.actors.all() for movie in movies]
> actors[0]
> QuerySet [<Actor: Nina>, <Actor: Paul>, <Actor: Ian>, <Actor: Catherine>]>
> len(connection.queries)
4
> actors[1]
<QuerySet [Actor: Nina>]>
> len(connection.queries)
5
위에서 볼 수 있듯이, 반복을 할때마다 추가 쿼리가 생기게 됩니다.
이제 prefetch를 이용해 같은 쿼리를 실행해보도록 하겠습니다.
> movies = Movie.objects.prefetch_related('actors').all()
> actors = [movie.actors.all() for movie in movies]
> actors[0]
> QuerySet [<Actor: Nina>, <Actor: Paul>, <Actor: Ian>, <Actor: Catherine>]>
> len(connection.queries)
2
> actors[1]
<QuerySet [Actor: Nina>]>
> len(connection.queries)
2위에서 볼 수 있듯이 쿼리의 갯수는 2개이며 첫번째 쿼리에서 데이터베이스의 모든 영화를 가져오고 두 번째, 세 번째 요청에서는 단일 쿼리만 발생하게 됩니다.
4. bulk method
일괄 처리는 쿼리를 검색하는 또 다른 성능 방법입니다.
데이터베이스에 여러 레코드를 추가할때 가장 효과적인 방법은 모든 개체를 한번에 만드는 것입니다. Django는 bulk_create() 를 제공합니다. 각 인스턴스를 한번에 생성 한 뒤 데이터베이스에 과부하를 주는 대신 모든 인스턴스를 커밋해 단일 저장 쿼리를 수행하게 됩니다.
Actor.objects.bulk_create([
Actor(first_name='Nina', second_name='Dobrev'),
Actor(first_name='Paul', second_name='Wesley'),
Actor(first_name='Ian', second_name='Somerholder'),
]또한 bulk_create and bulk_update()를 할 수 있습니다. 예를들어 특정 값으로 업데이트를 해야 한다고 가정하면 가장 효율적인 방법은bulk_update 를 사용하는 것입니다.
Model.objects.filter(name= 'name').update(name='someothername')5. RawSql
Django는 높은 수준의 쿼리 매커니즘을 제공하기 때문에 RawSQL은 권장되지 않습니다.
Django ORM을 이용해 모든 기능들을 처리할 수 있지만 떄로 필요할 수도 있습니다. Python이 아닌 데이터베이스에서 SQL 쿼리를 수행하면 성능이 더 빨라질 수 있습니다. 그러나 RawSQL은 최후의 수단으로 사용해야 합니다.
6. Foreign keys(외래키)
외래 키를 사용해 데이터베이스에 추가 부담 없이 데이터를 얻을 수 있습니다. 예를들어 트윗의 소유자를 얻기 위해 가장 효율적인 방법은 아래와 같습니다.
person = Person.objects.get(tweet__id =1)데이터베이스 작업 모니터링
프로덕션에선 데이터베이스 작업을 모니터링 하는것이 좋습니다. 이를 통해 데이터베이스에서 실행된 쿼리와 발생한 오류를 확인할 수 있습니다. Postgres 또는 Django 로그를 수시로 확인해 이를 수행할 수 있습니다. 이를 쉽게 하기 위해 Sentry를 사용할 수 있습니다.
Sentry는 Django 애필르케이션에서 데이터베이스 작업을 실시간으로 모니터링하기 위해 대시보드를 제공합니다. 데이터베이스와 관련된 오류를 실시간으로 확인하고 사용자가 발생하기 전에 해결이 가능합니다.
디버거가 없기 때문에 프로덕션에서의 오류를 인지하기 어려울 수 있지만, Sentry는 데이터베이스의 모든 오류를 볼 수 있도록 해 이 문제를 해결하고 있습니다.
시작을 하기 위해 여기서 Sentry 계정을 만들어 주세요. 사용중인 기술스택을 선택 창에서 Django를 선택해 프로젝트를 만들기(create Project)를 클릭합니다.
다음에 pip를 통해 Sentry를 설치합니다.
pip install --upgrade sentry-sdk마지막 단계로 settings.py에 공개키를 포함해 아래오 ㅏ같이 코드를 추가하면 됩니다.
import sentry_sdk
from sentry_sdk.integrations.django import DjangoIntegration
sentry_sdk.init(
dsn="https://examplePublicKey@o0.ingest.sentry.io/0",
integrations=[DjangoIntegration()],
# Set traces_sample_rate to 1.0 to capture 100%
# of transactions for performance monitoring.
# We recommend adjusting this value in production,
traces_sample_rate=1.0,
# If you wish to associate users to errors (assuming you are using
# django.contrib.auth) you may enable sending PII data.
send_default_pii=True,
# By default the SDK will try to use the SENTRY_RELEASE
# environment variable, or infer a git commit
# SHA as release, however you may want to set
# something more human-readable.
# release="myapp@1.0.0",
)Sentry를 이용해 애플리케이션을 모니터링 할 준비가 모두 되었습니다.
데이터베이스에 관련 오류를 생성해 Snetry가 원인을 보여줄 수 있는지 봅시다. 데이터베이스의 존재하지 않은 제품을 검색해 발생하는 샘플 오류입니다.
이 오류는 아래와 같이 Sentry 대시보드에 나타납니다.
Django는 데이터베이스를 모니터링 하는 Django Debug toolbar를 제공하여 요청 및 응답에 대한 프로세스를 실시간으로 확인할 수 있습니다. 또한 각 응답이 데이터베이스에서 데이터를 가져오는 시간을 확인할 수 있습니다.
Django debug toolbar를 pip로 설치하면 됩니다.
python -m pip install django-debug-toolbarDjango debug toolbar를 설치한 후엔 Django project에 설정을 해주면 됩니다.
아래 이미지는 Django debug toolbar가 동작하는 모습을 보여줍니다.
Django debug toolbar를 사용할때 단점은 페이지를 랜더할때 오버헤드가 추가됨으로 프로덕션에서 설정하는데 적절하지 않습니다. Sentry는 버그를 파악하고 데이터베이스에 대한 자세한 추적이 가능하도록 데이터를 제공하여 문제를 해결할 수 있습니다.