목차
728x90

Data Base
- 여러 사람들이 공유하고 사용할 목적으로 통합 관리되는 데이터들의 모임
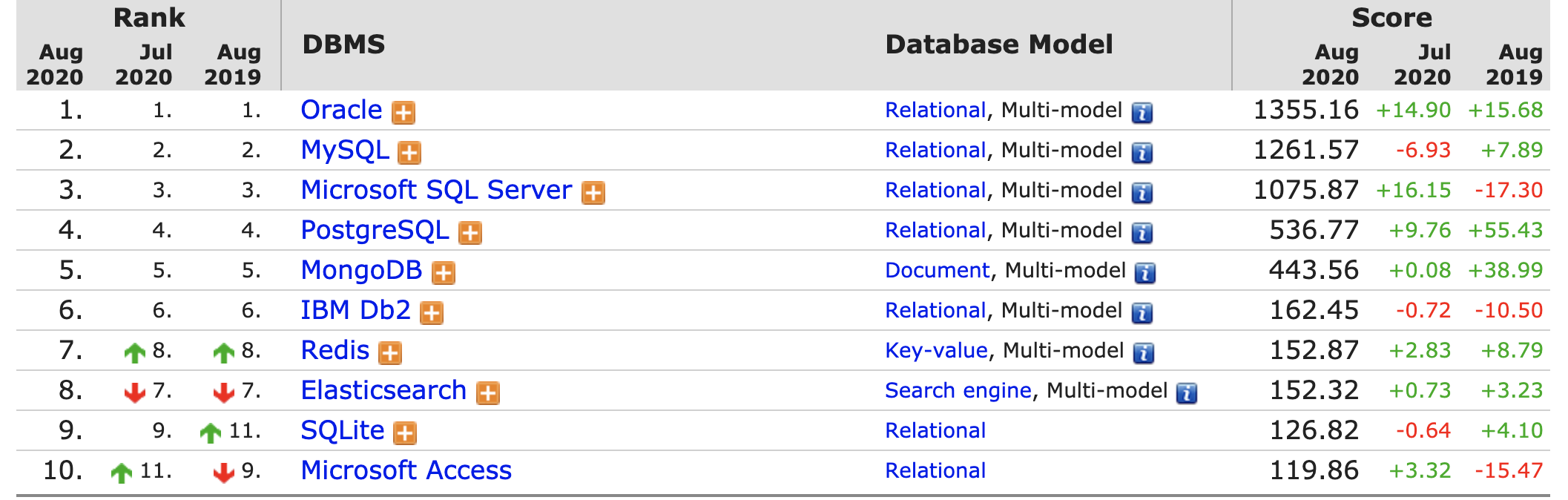
SQL(Structured Query Language)
- 데이터 베이스에서 사용하는 쿼리 언어로 데이터를 검색, 저장, 수정, 삭제 등이 가능하다.
수직적 vs 수평적 확장
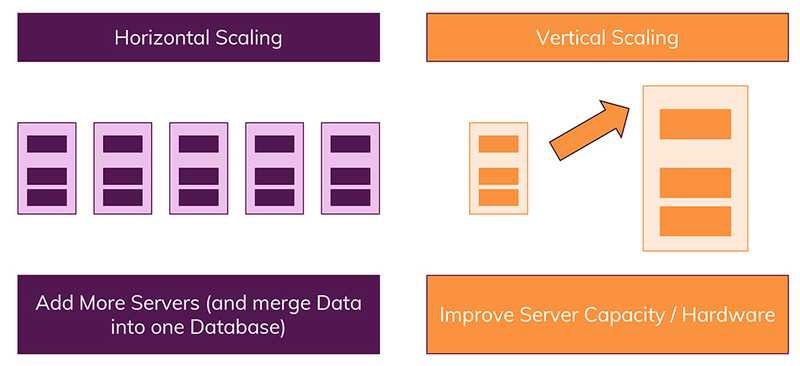
수직적(vertical) 확장(Scaling)
- 단순히 데이터베이스 서버의 성능을 향상시키는 것입니다.(예를 들어, CPU 업그레이드)
수평적(Horizontal) 확장 (Scaling)
- 더 많은 서버가 추가되고 데이터베이스가 전체적으로 분산된다. 따라서 하나의 데이터베이스에서 작동하지만 여러 호스트에서 작동한다.
RDBMS(Relational Database Management System)
- 관계형 데이터 베이스로 데이터를 구성하는데 필요한 방법 중 하나로 모든 데이터를 Key와 Value의 관계를 2차원 테이블 형태로 표현 해준다.
특징
- 데이터는 정해진 데이터 스키마를 따라 데이터베이스 테이블에 Column, Row 형태로 저장된다.
- 데이터 분류, 정렬, 탐색 속도가 비교적 빠르다.
- SQL 언어를 사용하여 데이터를 다룬다.
- 부하의 분산이 어렵다.
- 정해진 스키마에 따라 데이터를 저장하기 때문에 명확한 데이터 구조를 보장하며, 각 데이터에 맞게 테이블을 나누어 데이터 중복을 피해 데이터 공간을 절약할 수 있다.
- 시스템 복잡도를 고려하여 구조화를 해야 한다. 시스템이 복잡해 질수록 SQL문이 복잡해지고 성능이 저하되며, 수평적 확장이 어려워 수직적 확장을 대부분 하기 때문에 한계에 직면함.
- 일반적으로 수직적 확장만 지원.
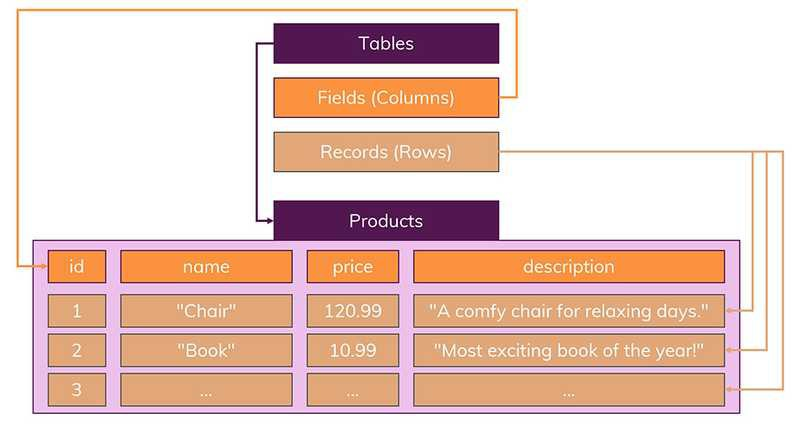
정해진 스키마
- 데이터는 Table에 Record로 저장되며 각 테이블에는 명확하게 정의된 구조가 있다.
- 여기서 구조란, 어떤 데이터가 테이블에 들어가고 어떤 데이터가 그렇지 않을지를 정의하는 필드 집합
- 위의 사진에서 처럼 Columns(Fields)에 맞지 않은 데이터는 추가할 수 없으며, 새로운 필드를 추가할때 스키마를 뜯어 고치지 않는 이상 필드 추가는 할 수가 없다.
관계
- 데이터들을 여러개의 테이블에 나눠서 데이터들의 중복을 피할 수 있다.
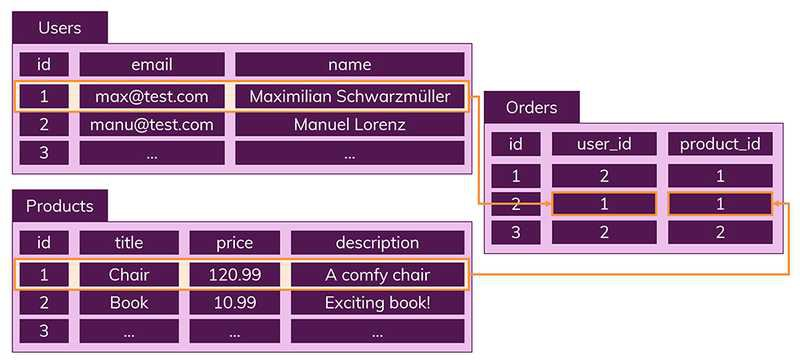
- 위의 사진 처럼 사용자가 구입한 상품들을 나타내기 위해 각각의 테이블을 만들었지만, 각 테이블은 다른 테이블에 저장되지 않은 데이터만 가지고 있으며, Join을 사용하여 원하는 데이터를 완성시킨다.
- 이런 명확한 구조는 장점이 있는데, 하나의 테이블에서 중복없이 하나의 데이터만 관리하기 때문에 다른 테이블에서 부정확한 데이터를 다룰 위험이 없다.
종류
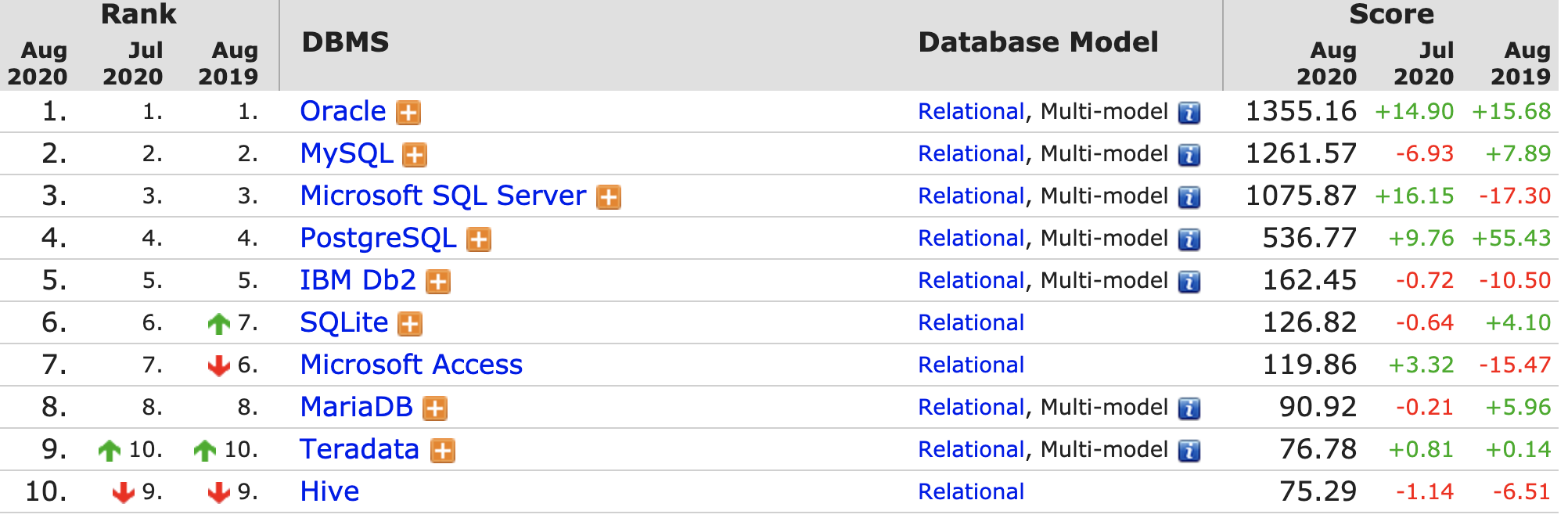
- Oracle

- MySQL

- Microsoft SQL Server

- Microsoft에서 개발한 것으로 윈도우에서만 사용이 가능
- PostgreSQL

- MariaDB

- Google, WordPress, Wikipedia 등에서 사용하며, MySQL 개발자에 의해 만들어져서 비슷한 부분들이 많다.
- SQLite

- 임베디드 시스템에 사용하는 RDBMS로 세탁기, 스마트폰, 자동차 등 사용이 많다.
RDBMS은 언제 사용하는 것이 좋을까요?
- 관계를 맺고 있는 데이터가 자주 변경(수정)되는 애플리케이션일 경우 (NoSQL에서라면 여러 컬렉션을 모두 수정해줘야만 합니다.)
- 변경될 여지가 없고, 명확한 스키마가 사용자와 데이터에게 중요한 경우
NoSQL(Not Only SQL 또는 Non relational Database)

- RDBMS의 복잡도와 용량 한계의 문제점을 해결하기 위해 나왔기 때문에 대용량의 데이터를 저장 할 수 있다.
- 이때 Table을 Collection이라고 보며, Record는 Documents라고 봅니다.
- Non relational 이름에서 보듯이 스키마도 없고, 관계도 없다.
- 즉, 스키마가 없다 보니, 다른 구조의 데이터를 같은 컬렉션에 추가할 수 있다. 즉, 관련된 데이터를 여러 Collections에 나눠 담지 않고 하나의 Collections에 저장한다. 따라서 Join을 할 필요 없이 모든 것을 갖춘 하나의 문서가 나오게 된다.
- 그러나 단점은 중복이 발생하게 되며 Data에 대한 규격화된 결과 값을 얻기가 힘들어진다.
- 수평적 확장이 가능.
- Key에 대한 put/get만 지원
종류
- Key / Value
- 휘발성 / 영속성
- 휘발성 / 영속성
- Document
- 스키마 정의가 없다.
- 스키마 정의가 없다.
- Big Table(Column) 또는 Wide Columnar Store
- 뛰어난 확장성, 검색에 유리
- Graph DB
- Nodes, Relationship, Key-Value 데이터 모델이 있다.
NoSQL은 언제 사용하는 것이 좋을까요?
- 정확한 데이터 구조를 알 수 없거나 변경 / 확장 될 수 있는 경우.
- 아주 낮은 응답 지연시간(latency)가 요구.
- 다루는 데이터가 비정형 데이터인 경우.
- 데이터를 직렬화하거나 역직렬화를 하기만 하면 되는 경우.
- 아주 많은 양의 데이터를 저장할 필요가 있는 경우.
In-Memory DB
- 디스크가 아닌 주 메모리(RAM)에 모든 데이터를 보유하고 있는 데이터 베이스
- 디스크 검색(HDD/SSD) 보다 자료 접근이 훨씬 빠르다.
- 데이터 양의 빠른 증가로 데이터 베이스 응답 속도가 떨어지는 문제 해결
- 단점은 안정성인데, DB 서버 전원이 꺼지면 자료가 모두 날라간다.
- Persistence 보장 하기 위해 파일에 메모리상의 데이터를 저장해두고 DBMS 재구동 시 디스크로부터 파일을 읽어와 메모리에 DBMS 구조를 모두 재구축하기도 한다.
- 안정성인 문제로 날라가도 상관없는 임시 데이터(로그인 세션 등)을 저장하는데 사용한다.
- 디스크 검색 방식은 디스크에 저장된 데이터를 대상으로 쿼리를 수행하지만, 메모리상에 색인을 넣어 필요한 모든 정보를 메모리상의 색인을 통해 빠르게 검색한다.
728x90
728x90
'Backend > DataBase' 카테고리의 다른 글
| SQL의 DDL, DML, DCL, TCL (0) | 2021.01.12 |
|---|---|
| 🤔 CASE WHEN ~ THEN ~ ELSE END (0) | 2021.01.11 |
| ORACLE, MYSQL 날짜에서 각 값들을 추출하기 🧐 (0) | 2021.01.07 |
| Transaction의 성질 - ACID (0) | 2020.12.19 |
| 개념 모델 vs 논리모델 vs 물리모델 (0) | 2020.10.30 |
728x90
Data Base
- 여러 사람들이 공유하고 사용할 목적으로 통합 관리되는 데이터들의 모임
SQL(Structured Query Language)
- 데이터 베이스에서 사용하는 쿼리 언어로 데이터를 검색, 저장, 수정, 삭제 등이 가능하다.
수직적 vs 수평적 확장
수직적(vertical) 확장(Scaling)
- 단순히 데이터베이스 서버의 성능을 향상시키는 것입니다.(예를 들어, CPU 업그레이드)
수평적(Horizontal) 확장 (Scaling)
- 더 많은 서버가 추가되고 데이터베이스가 전체적으로 분산된다. 따라서 하나의 데이터베이스에서 작동하지만 여러 호스트에서 작동한다.
RDBMS(Relational Database Management System)
- 관계형 데이터 베이스로 데이터를 구성하는데 필요한 방법 중 하나로 모든 데이터를 Key와 Value의 관계를 2차원 테이블 형태로 표현 해준다.
특징
- 데이터는 정해진 데이터 스키마를 따라 데이터베이스 테이블에 Column, Row 형태로 저장된다.
- 데이터 분류, 정렬, 탐색 속도가 비교적 빠르다.
- SQL 언어를 사용하여 데이터를 다룬다.
- 부하의 분산이 어렵다.
- 정해진 스키마에 따라 데이터를 저장하기 때문에 명확한 데이터 구조를 보장하며, 각 데이터에 맞게 테이블을 나누어 데이터 중복을 피해 데이터 공간을 절약할 수 있다.
- 시스템 복잡도를 고려하여 구조화를 해야 한다. 시스템이 복잡해 질수록 SQL문이 복잡해지고 성능이 저하되며, 수평적 확장이 어려워 수직적 확장을 대부분 하기 때문에 한계에 직면함.
- 일반적으로 수직적 확장만 지원.
정해진 스키마
- 데이터는 Table에 Record로 저장되며 각 테이블에는 명확하게 정의된 구조가 있다.
- 여기서 구조란, 어떤 데이터가 테이블에 들어가고 어떤 데이터가 그렇지 않을지를 정의하는 필드 집합
- 위의 사진에서 처럼 Columns(Fields)에 맞지 않은 데이터는 추가할 수 없으며, 새로운 필드를 추가할때 스키마를 뜯어 고치지 않는 이상 필드 추가는 할 수가 없다.
관계
- 데이터들을 여러개의 테이블에 나눠서 데이터들의 중복을 피할 수 있다.
- 위의 사진 처럼 사용자가 구입한 상품들을 나타내기 위해 각각의 테이블을 만들었지만, 각 테이블은 다른 테이블에 저장되지 않은 데이터만 가지고 있으며, Join을 사용하여 원하는 데이터를 완성시킨다.
- 이런 명확한 구조는 장점이 있는데, 하나의 테이블에서 중복없이 하나의 데이터만 관리하기 때문에 다른 테이블에서 부정확한 데이터를 다룰 위험이 없다.
종류
- Oracle
- MySQL
- Microsoft SQL Server
- Microsoft에서 개발한 것으로 윈도우에서만 사용이 가능
- PostgreSQL
- MariaDB
- Google, WordPress, Wikipedia 등에서 사용하며, MySQL 개발자에 의해 만들어져서 비슷한 부분들이 많다.
- SQLite
- 임베디드 시스템에 사용하는 RDBMS로 세탁기, 스마트폰, 자동차 등 사용이 많다.
RDBMS은 언제 사용하는 것이 좋을까요?
- 관계를 맺고 있는 데이터가 자주 변경(수정)되는 애플리케이션일 경우 (NoSQL에서라면 여러 컬렉션을 모두 수정해줘야만 합니다.)
- 변경될 여지가 없고, 명확한 스키마가 사용자와 데이터에게 중요한 경우
NoSQL(Not Only SQL 또는 Non relational Database)
- RDBMS의 복잡도와 용량 한계의 문제점을 해결하기 위해 나왔기 때문에 대용량의 데이터를 저장 할 수 있다.
- 이때 Table을 Collection이라고 보며, Record는 Documents라고 봅니다.
- Non relational 이름에서 보듯이 스키마도 없고, 관계도 없다.
- 즉, 스키마가 없다 보니, 다른 구조의 데이터를 같은 컬렉션에 추가할 수 있다. 즉, 관련된 데이터를 여러 Collections에 나눠 담지 않고 하나의 Collections에 저장한다. 따라서 Join을 할 필요 없이 모든 것을 갖춘 하나의 문서가 나오게 된다.
- 그러나 단점은 중복이 발생하게 되며 Data에 대한 규격화된 결과 값을 얻기가 힘들어진다.
- 수평적 확장이 가능.
- Key에 대한 put/get만 지원
종류
- Key / Value
- 휘발성 / 영속성
- 휘발성 / 영속성
- Document
- 스키마 정의가 없다.
- 스키마 정의가 없다.
- Big Table(Column) 또는 Wide Columnar Store
- 뛰어난 확장성, 검색에 유리
- Graph DB
- Nodes, Relationship, Key-Value 데이터 모델이 있다.
NoSQL은 언제 사용하는 것이 좋을까요?
- 정확한 데이터 구조를 알 수 없거나 변경 / 확장 될 수 있는 경우.
- 아주 낮은 응답 지연시간(latency)가 요구.
- 다루는 데이터가 비정형 데이터인 경우.
- 데이터를 직렬화하거나 역직렬화를 하기만 하면 되는 경우.
- 아주 많은 양의 데이터를 저장할 필요가 있는 경우.
In-Memory DB
- 디스크가 아닌 주 메모리(RAM)에 모든 데이터를 보유하고 있는 데이터 베이스
- 디스크 검색(HDD/SSD) 보다 자료 접근이 훨씬 빠르다.
- 데이터 양의 빠른 증가로 데이터 베이스 응답 속도가 떨어지는 문제 해결
- 단점은 안정성인데, DB 서버 전원이 꺼지면 자료가 모두 날라간다.
- Persistence 보장 하기 위해 파일에 메모리상의 데이터를 저장해두고 DBMS 재구동 시 디스크로부터 파일을 읽어와 메모리에 DBMS 구조를 모두 재구축하기도 한다.
- 안정성인 문제로 날라가도 상관없는 임시 데이터(로그인 세션 등)을 저장하는데 사용한다.
- 디스크 검색 방식은 디스크에 저장된 데이터를 대상으로 쿼리를 수행하지만, 메모리상에 색인을 넣어 필요한 모든 정보를 메모리상의 색인을 통해 빠르게 검색한다.
728x90
728x90
'Backend > DataBase' 카테고리의 다른 글
| SQL의 DDL, DML, DCL, TCL (0) | 2021.01.12 |
|---|---|
| 🤔 CASE WHEN ~ THEN ~ ELSE END (0) | 2021.01.11 |
| ORACLE, MYSQL 날짜에서 각 값들을 추출하기 🧐 (0) | 2021.01.07 |
| Transaction의 성질 - ACID (0) | 2020.12.19 |
| 개념 모델 vs 논리모델 vs 물리모델 (0) | 2020.10.30 |